Enhancing avalanche forecasts: the open avalanche project

An avalanche is just a fast-moving mass of snow down a mountain. That may sound simple but it doesn’t make it easy to predict.
Avalanches can be triggered by fluctuations in the snowpack, including heavy snowfall, a warm spell, an earthquake, or humans. (Some 90 percent of avalanche accidents are set off by the victim.) Annual avalanche accidents and fatalities in the United States have increased steadily, with the average national annual fatality rate climbing five times above the rate in the 1950s.
For the 2023 International Day for Disaster Risk Reduction, we’re talking to Scott Chamberlin who started The Open Avalanche Project. Launched in 2017, it aims to reduce avalanche-related deaths worldwide using machine learning to enhance the accuracy of avalanche forecasts.
We talk about how he got started, what community contributions he’s looking for and just how “open” the avalanche forecasting field is.
How did you get started?
I started with avalanche safety software when I created an app called Mobile Avalanche Safety Tools in a small company with one partner called Ullr Labs. At the time, it was the first avalanche field notebook for mobile phones, on both iOS and Android.
In that work, we established connections with avalanche forecast centers around the world as well as with many very passionate customers. In my discussions with these people, it was clear that the avalanche forecast was the primary source of information for most backcountry users. It was also clear that there were many opportunities for improvement in this space—much of which was due to a lack of funding and manpower to produce forecasts in areas that had none or with additional features.
It seemed to me like a great opportunity for machine learning to help address this scale challenge. It also was an interesting opportunity to help people and communities be safer in avalanche-prone areas.
“When you’re at the top of the slope and making a risk evaluation about skiing the slope, you want the best information available. The avalanche forecast is just one piece of this information to help assess the local conditions. Ultimately, having a suite of tools that draw on Open Source contributions from smart people around the world can advance this field.”
Scott Chamberlin
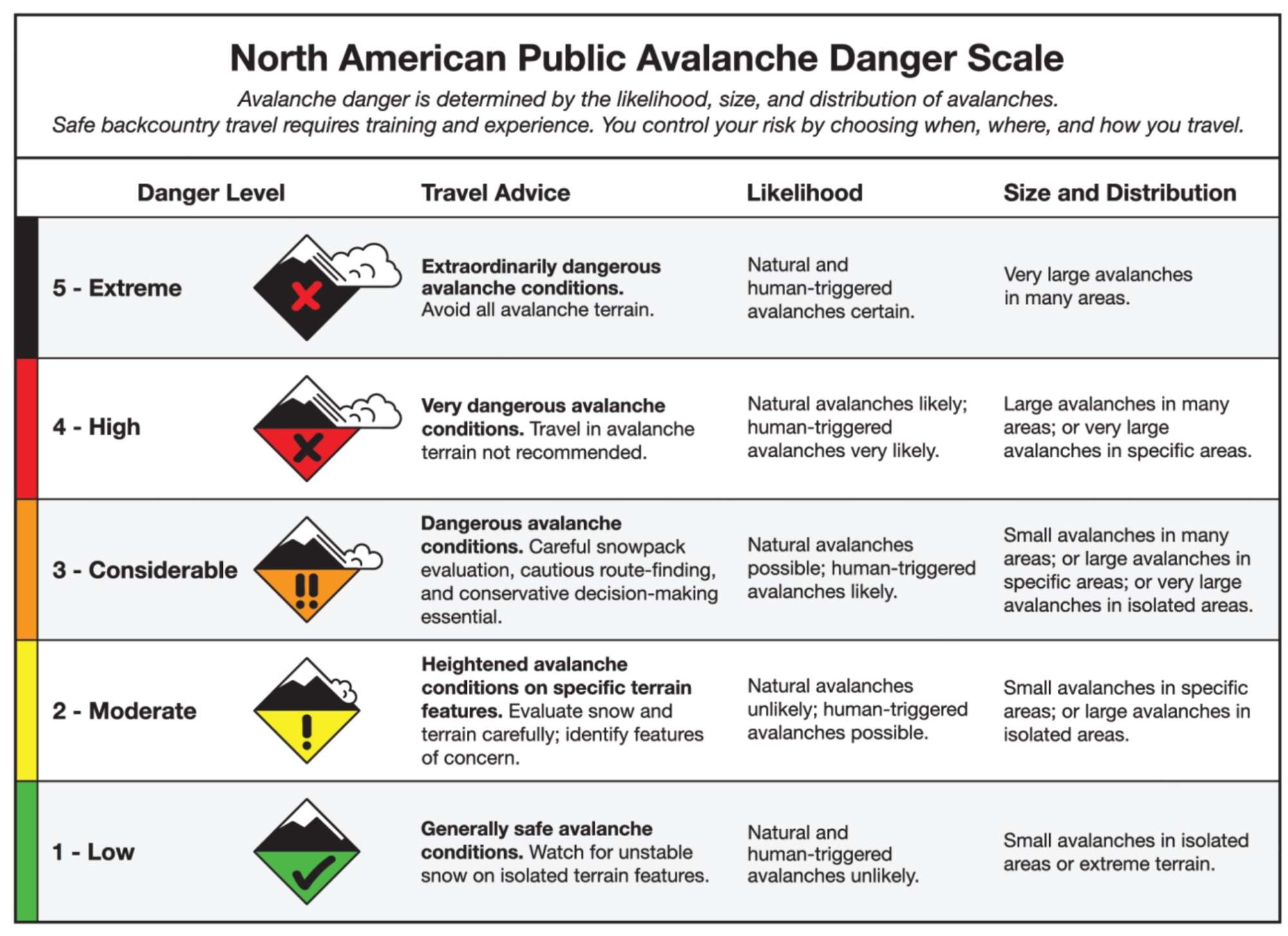
The North American Public Avalanche Danger Scale (NAPADS) rates avalanche danger and provides general travel advice based on the likelihood, size and distribution of expected avalanches. It has five levels, from least to highest danger: 1 – Low, 2 – Moderate, 3 – Considerable, 4 – High, 5 – Extreme. Via Avalanche.org
Do you do any backcountry sports?
How does avalanche awareness for backcountry sports folks (like those passionate customers for the Mobile Avalanche Safety Tools you mentioned) play into your project today?
Yes, I backcountry ski. Backcountry users are one of the main personas the project is focused on. When you’re at the top of the slope and making a risk evaluation about skiing the slope you want to be using the best and most accurate information available. The avalanche forecast is just one piece of this information and you can use the forecast to help assess the local conditions as part of your decision-making process. Ultimately, having a suite of tools that draw on contributions via Open Source from smart people around the world can advance this field and provide more accurate and more effective decision-making tools for these users.
What community contributions do you need now?
The avalanche forecasting community is relatively small and is relatively conservative due to the nature of the work and the safety implications of it. One nice thing is that much of that data comes from municipalities or governments and is generally in the public domain. There have been some good advances in making some of this data available for projects like the Open Avalanche Project. People beyond the project are working on it and small advances are made but it’s not always done in Open Source. That being said, the Open Source advancements in artificial intelligence and ML are advancing at a tremendous pace and when those general advancements are done in Open Source it’s easier for us working on domain-specific problems to try them out and adopt them. My hope is that we can provide something valuable and trustworthy to the community and that the open nature of it helps those aspects.
What are the challenges to getting higher accuracy rates with the ML model? Are there any specific areas where improvement is needed?
There are two big challenges:
- The input labels aren’t always accurate (i.e., the historical forecasts.) The state of the art for human forecasting is below 80% accuracy. When using that historical data to train a model, the model has to use techniques to overcome bad labels.
- The input data source isn’t always accurate. To achieve global coverage with a public domain model we use theGlobal Forecast System (GFS) forecast model from The National Oceanic and Atmospheric Administration (NOAA) and it isn’t the most accurate forecast model available. It also has a 12-kilometer grid so any variability below that level can’t be captured by the model.
Know Before You Go from Utah Avalanche Center on Vimeo.